Unpacking the Black Box:
How We Measure & run LLMs
~ Akshata Amara
Large Language Models (LLMs) are transforming technology, but their inner workings and costs remain opaque. We're not just going to explore the technical side; we're diving deep into the finances involved in LLM training and personal usage. This will clarify the buzz around cost-effective models like DeepSeek and help you assess the value of LLM subscriptions.
The Price of Power: Training Costs and Per-Prompt Expenses
Training advanced LLMs is a substantial financial undertaking. Models like GPT-4, with their vast parameter counts and extensive training datasets, incur costs ranging from tens to hundreds of millions of dollars. These expenses are driven by the scale of data processing, hardware requirements, and energy consumption. DeepSeek, however, emphasizes cost-efficiency, achieving significantly lower training costs through optimized model architectures and efficient resource utilization. They also report lower per-token usage costs compared to models like GPT-4. Essentially, DeepSeek aims to make powerful LLMs more economically viable.
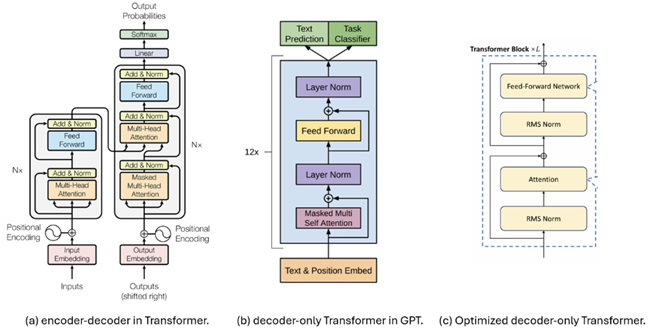
_Where did DeepSeek find the difference?
_DeepSeek's team found ways to build powerful AI without just throwing expensive NVIDIA chips at the problem. Instead, they made the AI smarter about how it does its work. They used a trick called "Mixture of Experts" so the AI only uses the parts of its brain it needs for each task, saving a lot of energy. They also made the AI "leaner" by getting rid of unnecessary connections, like cleaning up a messy desk. And they didn't rely only on one type of computer chip; they made their AI work well on different kinds of hardware. This smart approach means they can build strong AI models without spending as much money on super-expensive equipment.
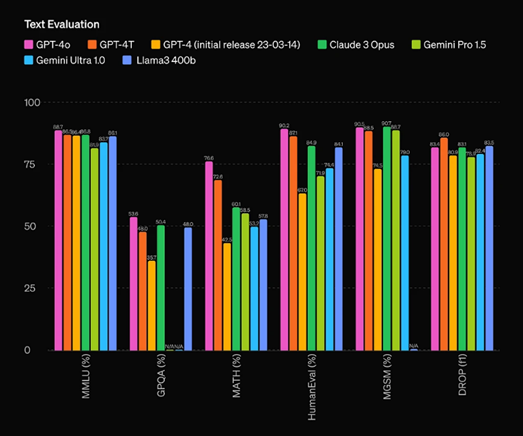
TL;DR: LLM training costs millions, but models like DeepSeek are working to bring those costs down, and per prompt costs down as well
Measuring the Magic: Beyond the Hype - How LLMs Are Evaluated
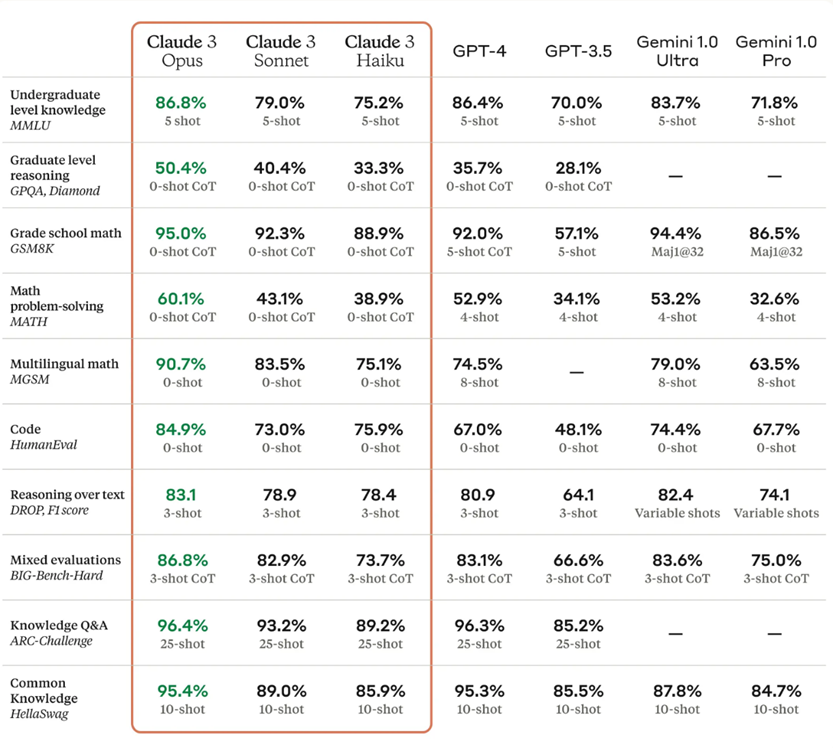
The buzz around the release of a new LLM seems to focus on math exam scores, or codeforces rankings, but how do they actually work, and are they relevant to an average user? In reality, evaluation involves a range of benchmarks that assess a model's holistic capabilities, focusing on practical applications beyond professional course exams.
Introduction: to-text-summarization-with-rouge-scores-84140c64b471/), which focuses on how much of the important information from reference summaries the model's text has.
Task-specific benchmarks, such as those for summarization, translation, or code generation (e.g., HumanEval, ensure models perform well in practical use cases. Contextual evaluation assesses a model's ability to handle nuanced language. Bias and fairness are measured through targeted tests that evaluate responses to diverse and sensitive prompts. Robustness is tested by evaluating performance with noisy or adversarial inputs. Efficiency is quantified by measuring computational resource usage, including time and memory.
Human evaluation remains crucial for assessing quality and safety, complementing automated metrics. Ultimately, LLM evaluation goes beyond flashy exam scores; it uses diverse benchmarks to measure real-world performance, context awareness, fairness, and efficiency.
TL;DR: Standardized tests and human evaluation measure how well LLMs perform in human-like writing, school level sciences, translation, etc., with a focus on practical applications and responsible use.
Running LLMs Locally: Hardware Requirements and Costs
Running LLMs on personal hardware requires powerful GPUs and sufficient RAM. The cost of a suitable GPU can range from several hundred to several thousand dollars, with models like the RTX 3090 or 4090 being popular choices. Smaller LLMs can run on consumer-grade hardware, while larger models may require professional-grade GPUs or even multiple GPUs. Libraries like Hugging Face Transformers provide tools for running LLMs locally, and techniques like quantization and model pruning can reduce hardware requirements. For example, a small model might run on a gaming PC costing $1000-$1500, while a larger model could require a $2500-$4000 setup. Running LLMs locally is becoming more feasible, but it requires careful consideration of hardware requirements and costs.
Want to actually download and run a model through your code?
Consider exploring HuggingFace, a platform which helps you pick and download a pre-trained ML model to run on the hardware of your choosing, including PCs with a basic 8 GB RAM and up; just note that these models will probably have high latency and lower context window length. Here’s a guide to downloading models on HuggingFace.
Choose Hugging Face models based on your task, performance metrics, hardware, community support, fine-tuning ease, and license. Smaller, task-specific, and popular models are often better for limited resources.
TL;DR: You can run LLMs at home with little technical knowledge, but you'll need a powerful computer, and the cost scales with the size of the model.
References
- https://crfm.stanford.edu/helm/latest/?group=mmlu
- https://github.com/google/BIG-bench
- https://aclanthology.org/W04-1013/
- https://towardsdatascience.com/rouge-score-in-natural-language-processing-84261796343e
- https://github.com/openai/human-eval
- https://towardsdatascience.com/choosing-and-implementing-hugging-face-models-026d71426fbe/
- https://neptune.ai/blog/hugging-face-pre-trained-models-find-the-best
- https://symbl.ai/developers/blog/an-in-depth-guide-to-benchmarking-llms/
- http://jalammar.github.io/illustrated-transformer/
- https://lilianweng.github.io/posts/2023-01-10-moe/
- https://learn.microsoft.com/en-us/ai/playbook/technology-guidance/generative-ai/working-with-llms/evaluation/list-of-eval-metrics
Image credits