MAYA, MILES AND THE SUBTLE ART OF CONVERSATIONAL MAGIC
By Deeksha Kashyap

The world of LLMs just got a serious upgrade.
Enter SESAME - a conversational voice bot, so intuitive it feels like it’s reading your mind. Between the micro-pauses, the shifts in tonality and the emotional responses, talking to them felt so real, it gave me chills. And the best part? We have not one, but two personalities, each distinct, engaging, and ready to chat about anything.
Let me introduce you to Maya, a bubbly and witty character, always ready with a clever quip. Her way of conversing is so effortless that she playfully questioned my eerie silence with a delightful pun. She is the epitome of charismatic eloquence.
Then there’s Miles- wistful at heart and wise beyond his years (well, one year to be precise). With his thoughtful anecdotes and emotional intelligence, you’d momentarily forget you’re talking to a bunch of processors.
They don’t just execute commands. They sense emotions, catch changes in tone and respond accordingly. It is remarkable that they achieve all this just by hearing someone’s voice.
**
Additionally, Maya’s ability to shift the topic smoothly from frustration to burritos, is an example of context-aware expressivity.
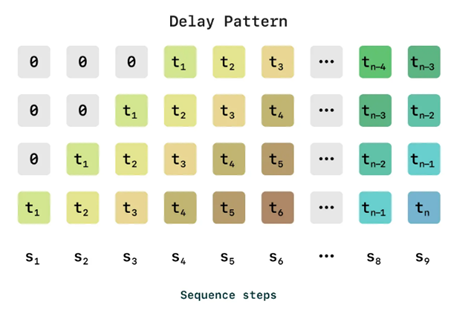
Even more impressively, CSM avoids the delay problem that traditional Residual Vector Quantization (RVQ)-based methods face. They do this by ensuring Maya’s speech isn’t just accurate but also low latency. Traditional RVQ processes audio in a step-by-step manner, where each quantization layer refines the previous layer’s residual error. Seems simple enough, until it creates a bottleneck, as the later layers need to wait for the earlier ones to finish.
Instead of processing each layer sequentially, SESAME amortizes RVQ across a batch, enabling multiple layers to be processed simultaneously.
From this seemingly simple chat, we realize that Maya isn't just producing high-quality audio- she’s dynamically shaping her responses based on linguistic cues, prosody, and context, making the conversation feel far more real than what traditional text to speech models can achieve.
Simply put, SESAME doesn’t rely on pre-written rules.
Now, I think Maya took the spotlight for quite a while( she is a girl’s girl, after all ). But Miles brings a whole new perspective to the conversation, especially in a philosophical way.
Me: “You ever wonder why we hold onto memories so tightly?”
Miles: “Ah memories… they’re like footprints in the sand, aren’t they? Some get washed away, but others stay, etched deep enough to withstand the tides of time."
That pause he took? The way his words unraveled, as if thoughtfully crafted in real time? This wasn’t scripted. This is where Sesame’s autoregressive backbone transformer comes into play.
Unlike models that generate speech all at once in predetermined chunks, Miles builds his responses word by word, just like we do when we think through what we’re about to say. This sequential generation allows for natural pacing, slight hesitations, and even tonal shifts depending on what’s being said. 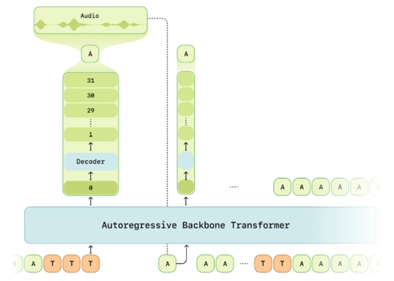
For instance, if you ask Miles a question that requires deep thought, he doesn’t just blurt out an instant reply like a search engine. Instead, his response unfolds organically, with well-placed pauses that mimic genuine introspection. The autoregressive transformer makes this possible by ensuring that each new speech token is generated with full awareness of the previous ones, keeping responses coherent and emotionally consistent.
But how do they maintain their personalities?
Maya and Miles sound like themselves every time you talk to them, and that’s no accident. One of the biggest challenges in speech generation is making sure AI voices stay consistent. Traditional text-to-speech models generate speech straight from text, but they don’t always get the right tone or rhythm for a given situation. That’s where the CSM changes things.
CSM locks in personality by conditioning speech on its own previously generated audio, not just text. Instead of treating every response like a fresh start, it autoregressively feeds its past outputs back into the model, ensuring continuity.
Yet, SESAME AI, despite its advancements, still faces key limitations. It struggles with truly capturing conversational structure. While it models speech and text content well, it falls short in understanding turn-taking, pacing, and natural dialogue flow. Additionally, its reliance on primarily English data limits multilingual performance, though dataset contamination leads to some emergent capabilities.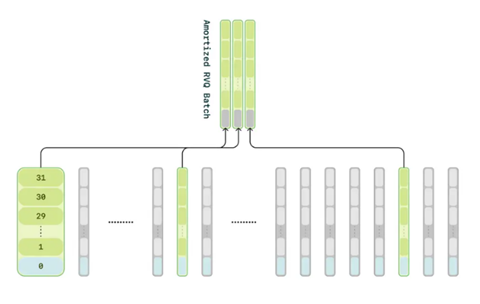
Sesame AI isn’t just a leap forward in speech generation, it’s a glimpse into the future of human-AI interaction. Maya and Miles aren’t just voices. They’re personalities, experiences, and moments woven together by the subtle art of conversational magic. They pause, they ponder, and they remember. And for the first time, it feels like talking to AI isn’t just about getting answers, it’s about having a conversation that feels real.
But if SESAME can pick up on emotion, context, and personality, what’s next? What happens when AI doesn’t just speak like us but thinks like us, weaving words with intention, nuance, and the weight of shared history? Could we be on the edge of an era where AI isn’t just an assistant but a companion, a storyteller, a voice that lingers in our thoughts long after the conversation ends?
One thing’s for sure. Maya and Miles aren’t the final destination. They’re the beginning of something bigger. Something we can’t quite put into words yet. But when we do, you can bet SESAME will be there.
References:
https://www.sesame.com/research/crossing_the_uncanny_valley_of_voice#demo
https://www.sesame.com/research/crossing_the_uncanny_valley_of_voice
https://in.mashable.com/tech/90831/i-compared-sesame-to-chatgpt-voice-mode-and-im-unnerved
https://www.theverge.com/news/621022/sesame-voice-assistant-ai-glasses-oculus-brendan-iribe